

By combining our core ontology management, pattern recognition and language processing technologies we can provide sophisticated and highly accurate document categorisation.
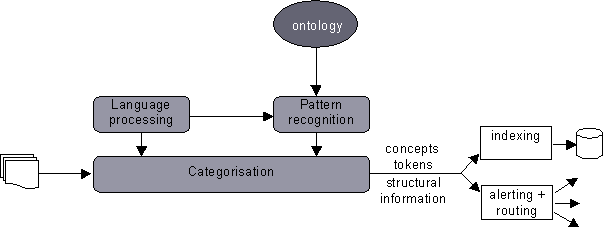
The ontology provides the schema and rules for the categorisation process. Documents are tokenised and any relevant stemming is applied, allowing the pattern recognition to find matching concepts in the ontology. The concepts are returned with a variety of relevance information indicating how relevant that document is to each concept. In addition a full breakdown of the document is returned, including information about sectioning and tokenisation.
The categorisation information is typically used in one of two ways. Firstly we may want to place the documents in an information retrieval system. The structural information and tokens can provide the data for free-text searching capabilities. The concept information can provide the data for concept-based retrieval. Secondly we may want to use the document analysis to decide how information is routed or distributed to users in an alerting system. For example users may subscribe to documents about a particular concept. Another example is to filter content, such as removing offensive emails.
The Exteca Ontology Model provides a mechanism for modelling domains of knowledge. Information specialists have long used similar structures called thesauri or taxonomies for the same purpose. The Exteca Ontology Model provides all the features of thesauri and more!
The ontology provides a controlled and shared vocabulary of terms. This
means that for a particular notion there is a very precise vocabulary that a
system will use for that notion. For example, we may realise that there is a
common vocabulary including words such as soccer
, football
and footie
, but we want to create a term called soccer
for our controlled vocabulary.
The use of controlled vocabularies is important for consistency, precision and completeness in a content management system. They provide the foundation for the structure of metadata repositories and end-user navigation systems.
Given a controlled vocabulary we can map a wide variety of content to the controlled
vocabulary to provide a consistent means to access it. For example we could
take news stories, magazine articles and web pages and categorise them by the
terms soccer
, tennis
and athletics
. We can
then place these documents in a repository such as a database and allow users
to search by category for this variety of content.
The Exteca Ontology model uses rules to map content to the domain described
by an ontology. This can produce results that are far more accurate than the
common prepared search
method that uses a small selection of words
to find matching content.
Here are some examples of rules for the concept soccer
:
'soccer' and('football', not('american football'))
The first rule simply says that the word soccer
signifies a relevance
of a document to the concept soccer. The second rule says that football
is a significant term, but only when not used in a document which contains the
phrase american football
.
The rules can also be used to find documents based on matching structural elements. Here we want to find a recipe that uses cheddar cheese and flour and is suitable as a main course: recipe(course('main'), ingredients('cheddar cheese', 'flour'))
The rules cover linguistic aspects such as stemming, plurals and case. Rules can be weighted to indicate their importance to the concept.
Using rules in this way we can build extremely accurate categorisation systems, with very high precision and recall rates.
Categorisation using the Exteca Ontology Model provides a number of metrics for each document and concept.
The score is a measure of how confident the system is that it has made the right categorisation decision. This can be used to provide a threshold by which the level of precision and recall in the system can be controlled.
The relevance is a measure of how well a document matches a concept. The Exteca system is unique in that it uses a two-dimensional measure of relevance, giving an indication of both how much of a document is relevant to the concept (the document relevance), and also how much of a concept is discussed in the document (the concept relevance). This eliminates the common problem where top hits for a search only contain one or two small pieces of relevant information.